
Longtemps cantonné aux films de science-fiction, l’agrandissement des photos sans perte devient de plus en plus efficace. Dernier exemple en date, celui de Google, via une méthode appelée « Super-Resolution via Repeated Refinements ». Très prometteuse, elle doit être capable de générer une image 4 fois plus définie, sans le moindre artefact parasite.

L’agrandissement des photos à portée de main
Souvenez-vous. Dans le film Blade Runner, le protagoniste, incarné par un Harrison Ford tourmenté, ordonnait – à l’oral ! – à son ordinateur d’agrandir une portion de l’image, passant d’une bouillie de pixel à une image ultra-détaillée. Un scénario qui s’est (hélas) longtemps heurté au principe de réalité.
Mais depuis quelques années, les progrès de l’intelligence artificielle ont permis à plusieurs éditeurs de proposer une solution pour agrandir ses photos sans perte. On pense à Topaz avec Gigapixel AI, à Pixelmator Pro, ou encore à Adobe Photoshop.
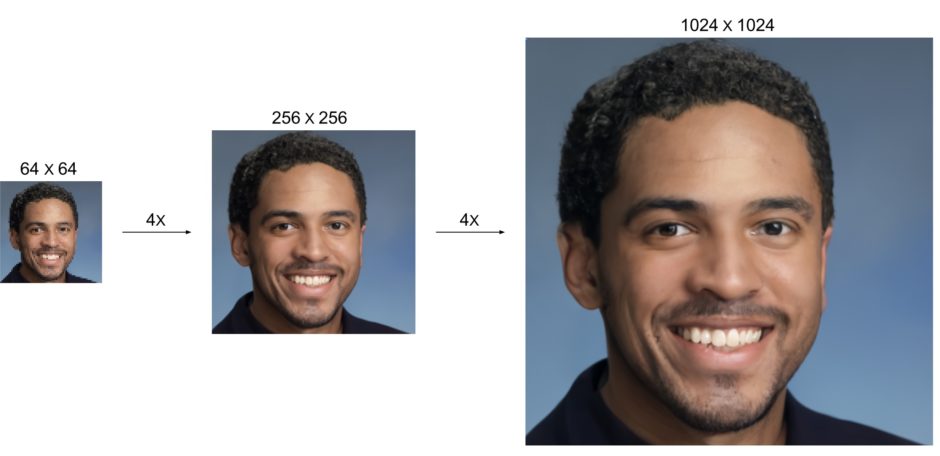
Toutefois, Google a l’intention d’aller beaucoup plus loin. Dans un récent article de blog, le géant de Mountain View a dévoilé les contours d’une nouvelle méthode, nommée « Super-Resolution via Repeated Refinements » (SR3, ou Super-Définition par améliorations successives en français). Son but : transformer une image de 64 pixels de large à une photo de 1024 pixels de côté.
Topaz Gigapixel AI : l’agrandissement de vos photos passe la seconde avec la v5.6
Ajouter du bruit numérique pour agrandir la définition d’une image
Le procédé employé est pour le moins surprenant. L’algorithme ajoute progressivement du bruit gaussien à l’image en faible définition. Pendant ce temps, il réalise un mapping très précis des variations des différentes régions de l’image. Une fois le fichier transformé en bruit pur, les algorithmes viennent appliquer un traitement visant à réduire le bruit.

En inversant le processus de dégradation de l’image, l’IA supprime le bruit et parvient à « reconstruire » la photo d’origine, mais dans une définition largement supérieure à l’originale.
Selon Google, le procédé peut être utilisé « en cascade ». Le but : passer d’une image de 64 x 64 pixels à une image en 256 x 256 pixels, puis à une photo en 1024 x 1024 pixels. Et les résultats présentés par Google sont tout simplement bluffants de réalisme, tant ils semblent proches de l’image « d’origine » en haute définition.

Pour y parvenir, les chercheurs de Google ont entraîné les algorithmes « à l’envers », avec des images en haute définition avec une dégradation progressive.
Ce nouveau procédé hyper-efficace pourrait être extrêmement utile pour restaurer des images en très faible définition (ah, les appareils photo numériques des années 2000 et leur capteur de 2 Mpx…). Toutefois, Google indique qu’il pourrait rendre de grands services dans le domaine médical, notamment.

Pour l’heure, les chercheurs de Google n’ont pas ouvert de plateforme permettant de tester ce nouveau procédé avec ses propres images. Mais nous sommes impatients de pouvoir tester cette méthode prometteuse.

Créer une image en haute définition à partir d’un simple mot-clé
Mais cette nouvelle méthode trouve aussi une autre application. En effet, elle permet à Google d’améliorer considérablement son système de création ex nihilo de (fausses) images plus vraies que nature… à partir d’un seul mot.

Baptisé Class-Conditional ImageNet Generation, il se base sur un simple mot-clé (setter irlandais ou cheeseburger par exemple). Un modèle de calcul génère une image en basse définition, suivi par une séquence de modèles de Super-Définition (SR3) en cascade pour accroître progressivement la définition des images.

Une méthode qui, d’après Google, s’avère beaucoup plus efficace que les méthodes employées par des solutions concurrentes, qui souffrent d’une certaine instabilité (source d’erreurs) et/ou qui s’avère beaucoup plus lentes.

Les chercheurs se disent conscient que leur méthode risque d’être utilisée « à des fins malveillantes » (coucou les deepfakes…). Ce procédé pourrait s’avérer fort utile pour améliorer la compression des données, et pour « faire avancer l’état des connaissances sur les problèmes fondamentaux d’apprentissage automatique ».
Et, plus prosaïquement, cette méthode pourrait accélérer la création de bases d’images labellisées. Pour mémoire, ces dernières utilisent des images où le sujet est clairement indiqué dans les tags du fichier. Et ces dernières pourraient justement servir aux algorithmes servant à la reconnaissance automatique des objets de nos photos.
